
This year SRECon NA was incredible and continues to hold a cherished spot on my conference calendar. It was attended by 600+ individuals, the majority of which was their first ever SRECon! I love that for us!
2024 marked the 10th year of SRECon and as Niall recounted in his keynote the 20th year for SRE as a profession. For me it marks my 2-year anniversary retiring from SRE and I wondered how much had changed and if I could still resonate and relate to the SRE experience...
Niall's keynote made many lovely points, one of which really stuck in my mind, that SRE, writ large, struggles to measure the value of our work.
^The toughest question I got during my talk Cognitive Apprenticeship in Practice last year was: "How did you get approval and show the value of learning for learnings sake?" Because the truth of the matter is...I didn't! It was one of the rare times that 2 levels of management missing and rolling up to what should've been my grand-grand-boss (aka VP of Eng) actually worked in my favor. No one in leadership was asking me to prove the value of this grassroots program or for that matter even knew about it until it gained some traction. (n.b. I don't recommend this approach but it is what it is)
Another salient point was the "operations is low status" battle has not been won. Big agree. When I told people of my SRE retirement I typically got two responses:
- 🥳 ops folks: congrats! good for you ops is janky, thankless, work. go forth and live that pager-free live in peace.
- 😟 everyone else: are you sure? do you want to try management? why do so many senior SRE women* leave?
Broad themes include tradeoffs, under-staffed and over-extended teams, and the importance of questioning commonly held ideas like “incident severity”and “phases of incident response”. So uh, while progress has been made (see less infighting, less making SRE an identity, and moving beyond SLO 101's) I found myself nodding along and empathizing with the tales from the field.

Overall was a whirlwind of learning, inspiration, commiseration and most importantly, community!
A Very Incomplete List of Talks I Watched
despite jam-packing my agenda with talks to watch (and making it to a total of 20!!) due to some prior commitments and scheduling conflicts, there's a big list of talks I couldn't catch IRL and am v excited to watch the recordings of.
caveat aside, here's the highlights from what I caught
Build vs. Buy in the Midst of Armageddon - Reggie Davis

Picture this: a team of 10 becomes a merry band of 3, drowning in a sea of issues, requests, and feedback. Unexpectedly, our team changed like a game of musical chairs, skills shuffling all over. In our pursuit to be the heroes, we hit the brakes and pitched buying a ready-made tool for a change. It wasn't just a business decision; it was a cultural rollercoaster for everyone involved! So, let's take a stroll down memory lane, exploring how we switched gears to evaluate third-party tools to pave the ground for improving the reliability of our platform.
Reggie walked through how chaotic SRE life is, especially when tenured engineers leave and take institutional knowledge with them and leaving junior to mid / less tenured SRE's in the lurch with more responsibilities and less team capacity.
As he laid out the situation he and his team were in I found myself nodding furiously. I got it, I have been there, in fact large parts of his story mirrored the year I had leading up to burnout and retirement. In a way its cathartic knowing the stress and predicaments I found myself in were not a solo experience. Even down to calling the reliability team the “kitchen junk drawer” a term I’ve totally used as well! Luckily for us all Reggie did NOT burnout and in fact navigated through these trying times and came out the other side having changed his company's culture, the SRE interview process/hiring criteria, and forged a stronger team.
The standout for me was "make a build vs. buy decision as if none of you will be at the company in 5 years time". YES!! Especially when it comes to internal tools and homegrown observability/monitoring systems....too often 1 dedicated SRE/infra/platform engineer who goes off cowboy coding can create a whole pile of custom complexity that becomes load bearing infra/tool without buy in or design reviews from everyone. Its awful for the SREs who come after.
I applaud Reggie for his vulnerability and openness sharing the full story of this incident management tool including alllll the ups and downs and the u-turn after the initial build decision didn't pan out. These are the stories we need to be sharing! The how and why behind decision making, the tradeoffs and constraints!
Thawing the Great Code Slush - Maude Lemaire
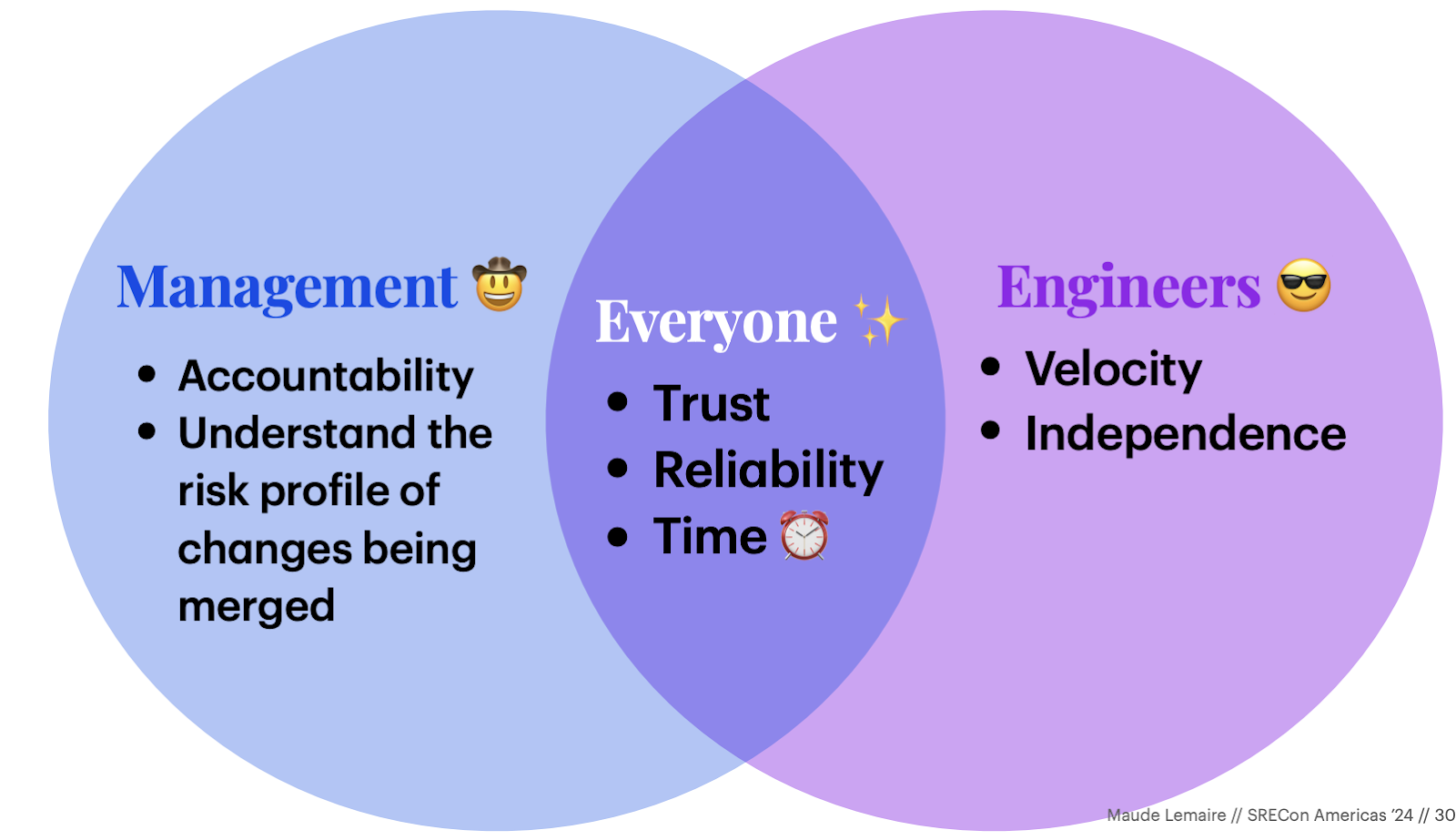
October 2020 wasn't a great month for Slack. Plagued with multiple hours-long outages, our engineering leadership team called for a code slush: all pull requests to our build and configuration mono-repo, aptly named "chef-repo", would need to be reviewed live, over Zoom, by a change advisory board (CAB) until further notice.
Five months later, CAB was still alive and well. We'd made some ergonomic improvements to the process, but development for our infrastructure team had slowed to a crawl.
Armed with a beginner's mindset– I'd only committed to the repo once under the new process– I decided to take matters into my own hands. What follows is a tale of building trust, making compromises, and slowly, but surely restoring our long-lost productivity without eroding reliability.
For those fighting the good fight against code freezes at your org...this talk will give you plenty of inspiration and a paved path. "If Slack can forgo a Change Advisory Board...why can't we?".
Excellent slides, excellent stage presence, excellent content.
The Art of SRE: Building People Networks to Amplify Impact - Daria Barteneva

If SRE were a well-defined science, we wouldn't need too much mentoring/coaching/cross-team groups. We could just do "the thing" and be done with it. But the truth is that our profession needs a significant component of human interaction to unlock a degree of success that would be unattainable without it.
You’ll learn about how our voices make sound, how choirs integrate newer voices while maintaining harmonious resonant sound (so cool!) AND how to borrow that practice of implicit coaching to help SREs build and practice critical skills.
Daria's talk cuts right to the heart of what I identified earlier as "existential risks if we don't collectively share systems knowledge across generations and cultivate meaningful learning experiences."
This is one of those talks you hear and then immediately want to go put into practice 😄
The Invisible Door: Reliability Gaps in the Front End, Isobel Redelmeier
It's hard for anyone to experience our services' many nines if our apps keep crashing. Front end reliability is critical to keeping our users happy - so how can we reliability engineers help improve it?
This talk will explore the unique technical and organizational challenges facing the front end, with particular emphasis on observability. Through specific examples from my experience as an SRE working on mobile reliability, you will learn about hurdles like how difficult it can be to add even basic metrics as well as get inspired by how well-connected front end tooling is to business analytics. Ultimately, we'll imagine what a more holistic approach to reliability could look like and consider a path to achieving it.
No CSS knowledge required :)
A few months ago I was asked where someone could find SRE's with front-end expertise and to be honest...I busted out laughing and said good luck with that purple squirrel 🐿️ 💜.
Its no secret that SRE and even observability and even OpenTelemetry over-rotate on serving folks working on the backend and with databases and I was so glad for Isobel's presentation and the flurry of discussion it launched afterward.
Want to find high cardinality metrics? look no further that FE! 2 core vitals x 3 release channels x 1000 version x 20000 device models = 12,000,000 possible dimensions #TIL
Isobel also presented a currently unsolved problem "how do you catch a crash that happens before the Sentry SDK is initialized?"
Just as Amy Tobey tasked us with making a friend in sales...I think in the spirit of Isobel's talk you should go out right now and make a friend on the front-end and see what you can learn 😄
99.99% of Your Traces Are (Probably) Trash - meeeeee

Oh distributed tracing, how I believe in your power and how I fret about your slow adoption and steep learning curve. It was ~6 years ago that I unfurled my first trace waterfall as a young SWE-1 and had my mind absolutely blown. I had no mental models or entrenched patterns relying on bopping between metrics dashboards and inscrutable logs. I had beautiful traces that told the story of what the heck was actually happening in production. In the years since I've leaned on traces to onboard myself to new teams and new companies, to optimize CI/CD pipelines and more!
Since then I've been on a not-so-secret mission to invite everyone to the distributed tracing party 🎉. I will confess to having a bit of tunnel vision about tracing early on, at one point proclaiming "one day there will be no logs, only traces" and meaning it 😅. It took me a couple years, some painful observability migrations, and many many conversations with peers and luminaries to understand:
- why tracing didn't and wouldn't get the same overnight adoption as APM
- that tracing has a place in contemporary telemetry but will not replace telemetry types like native metrics.
all of that preamble to say rolling out distributed tracing without a sampling strategy for your organization risks introducing perf hits to your applications, tipping over Collectors, and observability budget overruns. Each of those things make tracing feel scary and risky to management, SRE and developers and really cramp the open, curious and exploratory vibe you want to be cultivating.
Slides here, recording to follow in a couple months, and extra resources on out-of-the-box sampling options with OpenTelemetry you can use today to come soon!
If you find the constraints of head and tail sampling options today stifling...then I have good news for you both Sifter: Scalable Sampling for Distributed Traces, without Feature Engineering and its predecessor The Benefit of Hindsight: Tracing Edge-Cases in Distributed Systems offer new radical approaches to sampling that I believe could be the ~ future ~. Since OpenTelemetry is...well..open, there's nothing to stop you from designing a similarly sophisticated sampling system to plug into the Collector. If you're embarking on this work or are doing cool custom sampling setups reach out! I would love to hear more.
My Fave Swag
If you didn’t swing by the Antithesis booth you majorly missed out on fruitful convos about what even is a continuous reliability platform and some neat bugs Antithesis has already uncovered.
and the best swag I've gotten from any conf...ever this lil windup toy named Le Pinch

I cannot tell you how much fun my partner and I had making little obstacle courses for it to traverse. And what a fun metaphor/parallel for the bugs "crawling" around your system!
See you in Dublin?
Writing this up has got me missing SRECon already and it's a good thing CFPs are open for SRECon EMEA 😏
Presentations I'd like to see/give
- SRE Perspectives panel featuring a new grad/intern, a mid-level SRE, senior SRE, and Staff SRE (would be down to moderate this one!)
- would also be interested in hearing from SRE at different sizes of orgs - SRE at a startup vs regional mid-size company vs multi-national company vs government
- Career Crossroads aka what transferable skills do SRE have? what are adjacent roles you could transition to? (would love to hear from an internal infrastructure/reliability product manager)
- Taking Out the Tracing Trash - A deeper dive into available sampling strategies with OTel (maybe a workshop?) , more use cases/examples?
- Service Ownership - does your org have a clear definition of service ownership and the responsibilities an app dev has vs an SRE? How is it "enforced"? How did the definition come to be and how is it adapted over time?
lmk what topics are top of your mind
CAT TAX

Comments