
Several months back the marketing department gathered for an in-person offsite in Nashville. After a long day traveling across the States all I wanted was to put in a dinner order, check in, and loaf in my room in peace. That was the plan anyways. In the taxi ride over I attempted to look up the hotel’s dining menu and instructions. Instead of the homepage, I was greeted by this barebones error page that is clearly some default messaging intended only for engineers.
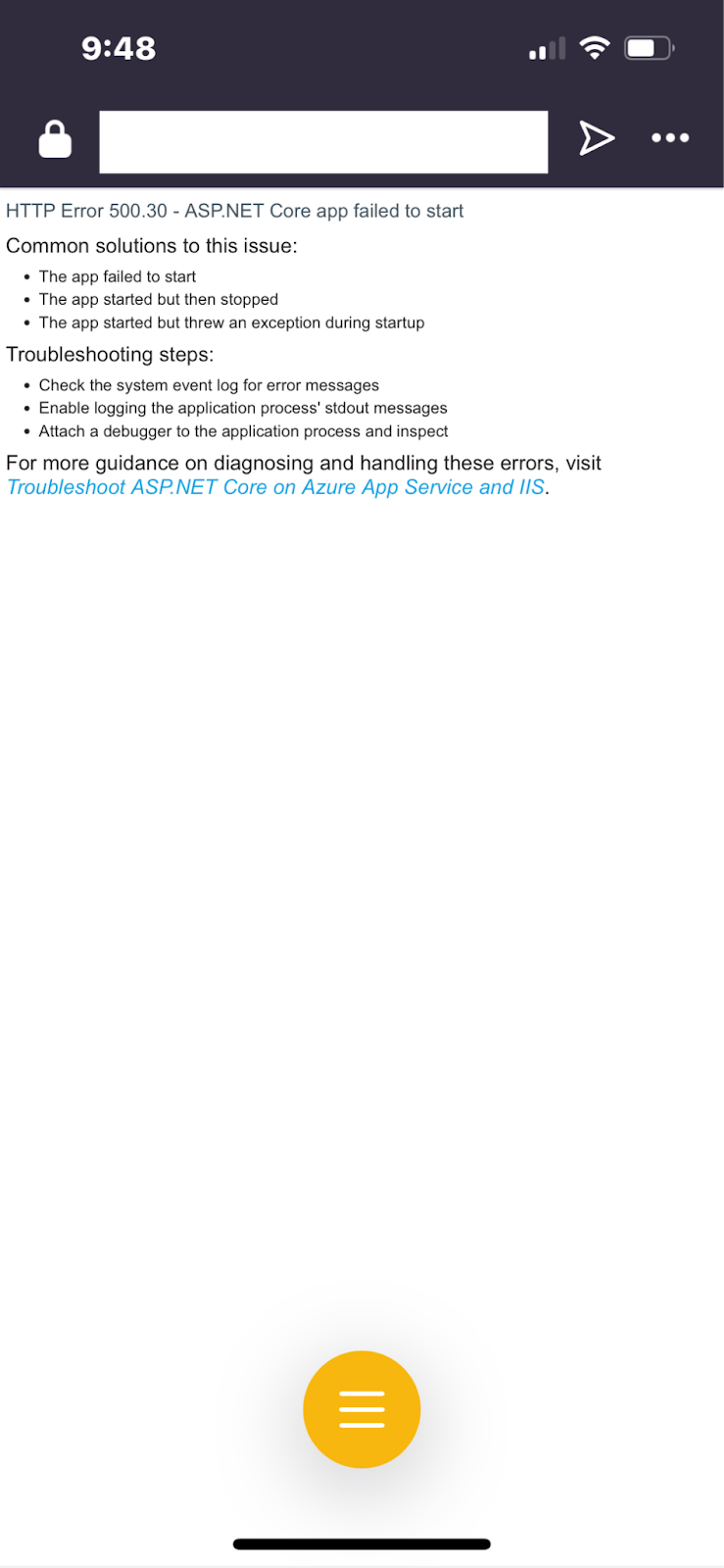
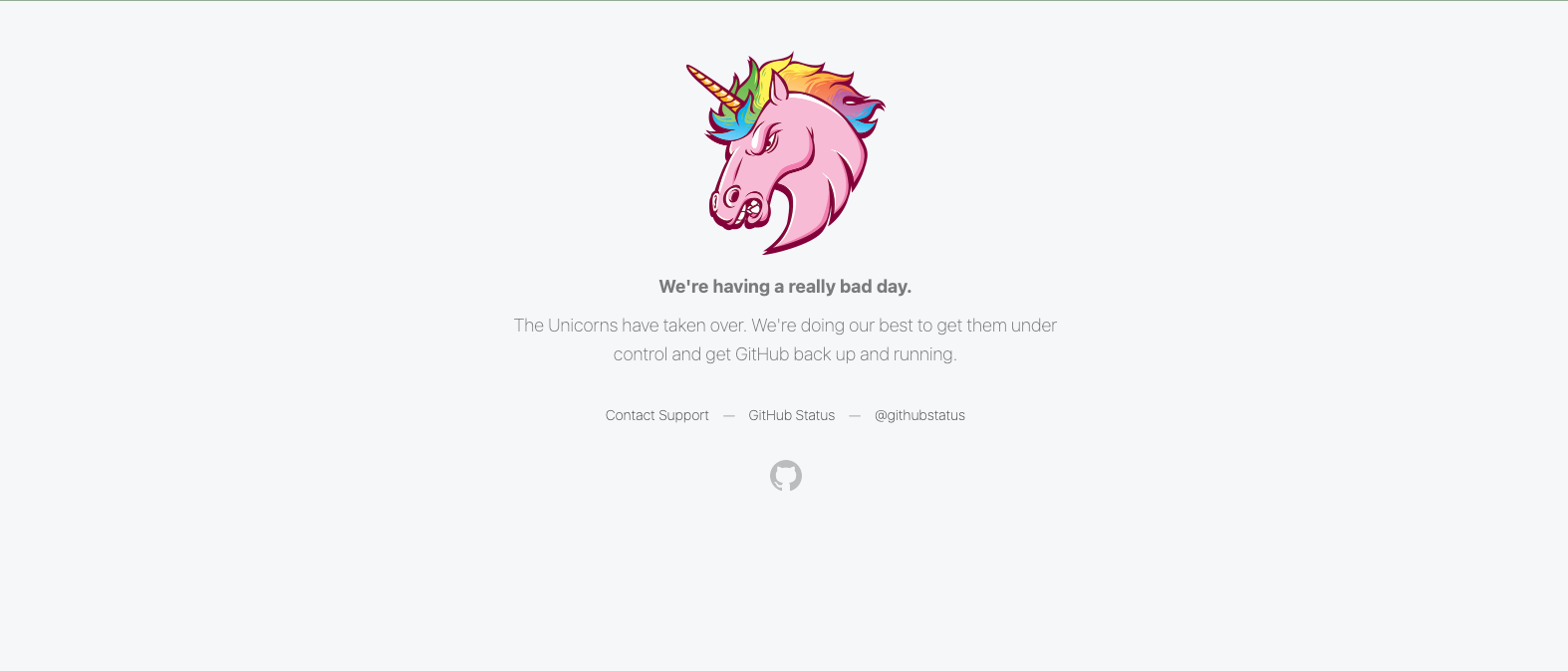
I’m not asking for Picasso-worthy designs either, even the minimalistic pink unicorn from GitHub would work. At the very least replacing the error message with something customer-friendly like “We’re aware of an issue with our site and are working on it. In the meantime, to checkmeantime to check on reservations, call us at 555-555-5555.”
“Must be a glitch” I thought to myself and I did what 54% of consumers do when faced with this situation: and refreshed the page. No dice. I was still 30 minutes away and figured a total site outage must already be on their radar and would be fixed by the time I arrived. Bad assumption. When I approached the reception desk to check-in, I refreshed one last time and was kind of shocked to see that the site was still unavailable. At this point I realized the hotel probably didn’t even know their site was and had been down and reported it to the concierge.
While I may not have been the first customer to notice, I was the first to report this outage that affected the websites for the entire chain of hotels in this group. The evening ended with me rolling my suitcase upstairs, chowing down on some southern food and of course occasionally checking the hotel site to see when it would come back online (it took another couple hours after check-in fwiw). All in all, the outage had a minimal impact on my overall experience.
My inner SRE wondered when the site first went offline, how long the outage would have lasted if I hadn’t notified them, how many users also saw that default 500 error page, and what their approach to monitoring was. I will never know the answers to those questions but was left with a reminder that in a time when observability dominates discussions, monitoring continues to play a key and overlooked role.
CAT TAX

-- paigerduty
Comments